
同時接続数 MaxClients値の選定
今更ながらに、ApacheのMaxClients選定について
Apacheの大切なチューニングポイントの一つに、MaxClientsの選定があります。
この値はWEBサーバ1台あたりの同時リクエストを捌ける数に関係するので、できるだけ大きい方が都合がいいです。
でも、大きすぎるとマシンのメモリを使い尽くし、スワップがあればスラッシングが頻発しますので、
レスポンスが逆に低下します。
そのため、
このMaxClientsの最適値は、そのサーバ自身のOSが使用するメモリを除いた、
搭載メモリサイズを最大限使用できるギリギリの値になります。
なので、
- 1プロセスあたりの平均接続時間
- 1プロセスあたりの平均使用メモリ
あたりが、
選定する際に考慮する点になります。
■接続時間に関するチューニングパラメータには、
- KeepAlive (ON or OFF)
- MaxKeepAliveRequests (数値)
- KeepAliveTimeout (数値)
があります。
- KeepAliveは、Keep-Aliveの有効/無効
- MaxKeepAliveRequestsは、接続を保持する最大リクエスト数
- KeepAliveTimeoutは、接続保持時間
を設定できます。
Keep-Aliveを有効(ON)にすると、HTTPリクエストあたりの接続に対するオーバーヘッドはなくなりますが、
1リクエストあたりのコネクション占有時間が長くなるため、同時接続が増えてきた場合には、
メモリを食い尽くす可能性が上がります。
perlの場合、
mod_perlと(Catalystのような)WEBフレームワークを使用している場合は、
平均1プロセスあたり50MB~100MB使用しますので、
そのようなサーバでメモリを十分に積んでいないサーバのKeepAliveはOFFにすべきです。
■使用メモリ量
psコマンドでRSS(実際に割り当てられている物理メモリサイズ)を確認できます。
httpdでgrepするといいと思います。
% ps auxww | grep httpd
このRSSの値にはLinuxのCopy on Write機構によって、
親プロセスとforkされた子プロセスで共有しているメモリも含まれ表示されていますので、
実際の1プロセスあたりの使用メモリは、
「正味メモリ = RSS – 共有メモリ」
になります。
なので、
MaxClientsの算出方法のアウトラインとしては、
OSや他システムでの使用メモリやリクエスト接続時間を考慮した上で、
「MaxClients = 搭載メモリ / (RSS – 共有メモリ)」
になるかと思います。
■共有メモリを確認方法としては、以下のようなスクリプトを組むといいです。
[perl]
#!/usr/bin/perl
use strict;
use warnings;
use Linux::Smaps;
@ARGV or die "usage: %0 [pid …]";
printf "PID\tRSS\tSHARED\n";
for my $pid (@ARGV) {
my $map = Linux::Smaps->new($pid);
unless ($map) {
warn $!;
next;
}
printf
"%d\t%d\t%d (%d%%)\n",
$pid,
$map->rss,
$map->shared_dirty + $map->shared_clean,
int((($map->shared_dirty + $map->shared_clean) / $map->rss) * 100)
}
[/perl]
Linux::Smapsはコアモジュールではないため、インストールがめんどくさい人はこっち。
[perl]
#!/bin/env perl
use strict;
use warnings;
use List::Util ();
@ARGV or die "usage: %0 [pid …]";
my @output;
for my $pid (@ARGV) {
die "invalid pid ‘$pid’" if $pid =~ /\D/;
my @smaps = `cat /proc/$pid/smaps`;
die if $? != 0;
my @shared = map { /(\d+)\s+kB/; $1 } grep { /^Shared_(Clean|Dirty)/ } @smaps;
my $shared_total = List::Util::sum(@shared);
my @rss = map { /(\d+)\s+kB/; $1 } grep { /^Rss/ } @smaps;
my $rss_total = List::Util::sum(@rss);
my $parcent = sprintf ‘(%d %%)’, int(($shared_total / $rss_total) * 100);
push @output, [$pid, $rss_total, $parcent];
}
unshift @output, [qw(PID RSS SHARED)];
for my $out (@output) {
print join "\t", @$out;
print "\n";
}
[/perl]
※参考
http://d.hatena.ne.jp/naoya/20080212/1202830671
http://d.hatena.ne.jp/yumatsumo/20110805
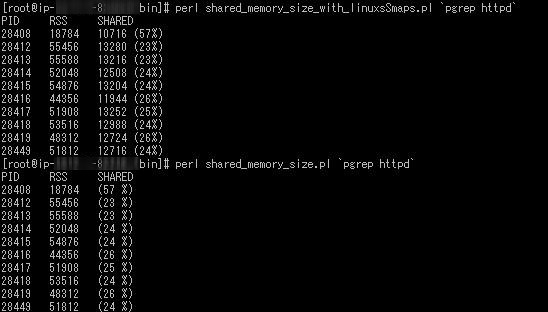
% perl shared_memory_size.pl `pgrep httpd`

どっちも、同じ数値ですね。
この記事が気に入ったら
いいね!してね
最新情報をお届けします!
この記事が気に入ったら
いいね!してね
最新情報をお届けします!